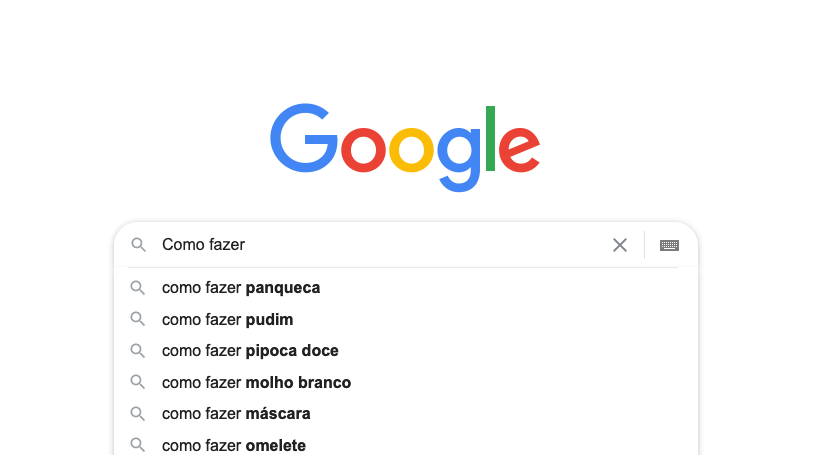
Você já teve curiosidade em saber como o Google prevê qual a próxima palavra que você vai digitar em uma pesquisa?
Isso é feito através de uma tarefa conhecida como Next Word Prediction ou Language Modelling. Essa tarefa é uma das mais básicas do Processamento de Linguagem Natural (PLN), e também é usada em teclados de smartphone, e em muitas outras aplicações, como as que envolvem sumarização de texto, por exemplo.
Neste post, apresento um pequeno tutorial de como fazer um preditor de próximas palavras utilizando Redes Neurais implementadas com a ferramenta TensorFlow.
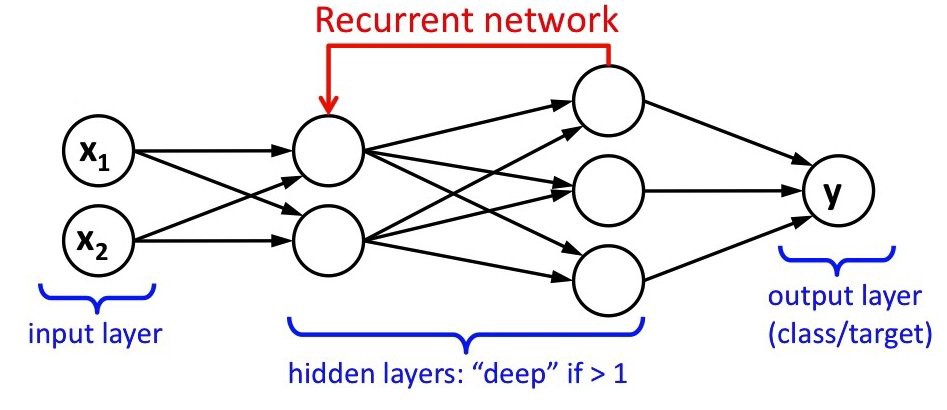
Redes Neurais Recorrentes
Redes Neurais são modelos matemáticos usados na computação para a aprendizagem de máquina e cujo objetivo é simular o sistema nervoso de um animal para “aprender” coisas úteis para uma tarefa. Por exemplo, aprender como uma palavra pode ser traduzida para outro idioma é útil para um sistema de tradução automática. Ou para um transcritor, como o nosso Transcritor Élfico.
Essas redes são formadas por neurônios artificiais interconectados, que computam valores de entrada para fornecer uma saída, simulando o funcionamento de um neurônio biológico. Esses neurônios são unidades de processamento que interagem entre si e estão organizados em camadas. É da interação entre os neurônios e as camadas que vem a capacidade de inteligência da Rede Neural.
Quando o conteúdo é passado mais de uma vez pela rede neural para reforçar o aprendizado, ela passa a ser chamada de Rede Neural Recorrente. O seu uso leva em consideração que o que é aprendido por um neurônio biológico não deve ser esquecido, mas reutilizado para “refinar”o aprendizado.
Vamos ao código
Redes Neurais Recorrentes podem ser implementadas com a ferramenta TensorFlow, dentre outras, que é uma biblioteca de software para aprendizagem de máquina mantida pelo Google. Essa ferramenta fornece uma interface que torna a construção de aplicações de aprendizagem de máquina mais simples.
No nosso exemplo, nós usaremos a API Keras, que tem o objetivo de reduzir o esforço cognitivo necessário para a construção de modelos de aprendizagem de máquina. Portanto, vamos começar instalando essa API e outras dependências do nosso projeto:
Base de treinamento
Com tudo instalado, o que precisamos agora é preparar a nossa base de treinamento, que é de onde a nossa rede neural vai aprender a predizer a próxima palavra.
Nós usaremos um corpus (documento de texto) em português brasileiro, extraído a partir de notícias do site da Revista Pesquisa FAPESP. Você deve baixar o corpus usando este link e salvá-lo na pasta data, ou executar a primeira linha do trecho de código abaixo no seu terminal. Depois, precisamos extrair os arquivos baixados (segunda linha), e extrair a parte do corpus que é em português.
O script Python a seguir tem a função de compilar os arquivos do corpus em um único TXT com texto plano. Nele é possível definir a quantidade de arquivos serão utilizados, uma vez que o corpus é muito grande e, dependendo da capacidade de processamento da máquina, usar ele por inteiro poderia fazer o modelo levar muito tempo para ser treinado. De todo modo, fica ao seu critério. Se quiser utilizar o corpus inteiro, só apagar o trecho [:FILES_NUMBER] do script.
Treinamento
Primeiro vamos importar as bibliotecas necessárias no treinamento:
Depois, carregamos a base de treinamento.
Então, utilizamos um tokenizador para dividir o corpus em tokens, ou seja, em palavras.
Em seguida, precisamos ter a lista das palavras únicas presentes no corpus. Além disso, precisamos de um dicionário (<chave: valor>) com cada palavra da lista de palavras únicas como chave e sua posição correspondente como valor (e.g., <clube: 128 , dos: 129, …>).
Engenharia de Features
Em Aprendizagem de Máquina features são características que descrevem um determinado recurso de aprendizagem. Por exemplo, se você construir um modelo para identificar objetos em fotografias, é natural que as features sejam características desses objetos (cor, tamanho, forma, etc.).
Em se tratando de texto, as features podem ser informações sobre como as palavras estão dispostas nas frases, ou como elas se relacionam, etc. No nosso caso, usaremos como features as palavras que antecedem aquela que desejamos predizer. Para isso, definimos a variável SEQUENCE_LENGTH, que determina a quantidade de palavras anteriores que usaremos na predição. Além disso, criamos uma lista vazia chamada prev_words, onde as palavras anteriores serão armazenadas, e uma lista next_words para as suas “próximas palavras” correspondentes. Preenchemos essas listas fazendo um loop em um intervalo de 3 menor que o comprimento das palavras.
Depois, criamos dois arrays utilizando a biblioteca numpy: X para as features e Y para os rótulos correspondentes, ou seja, as próximas palavras.
Esses arrays podem parecer estranhos à primeira vista, mas vale destacar que esse tipo de encoding, conhecido como One Hot Encoding torna a aprendizagem e a predição mais eficiente, como explicado no vídeo abaixo (ative as legendas):
O nosso modelo
Nós usamos um modelo LSTM com uma única camada e 128 neurônios, uma camada de conexão (Dense), e a função softmax para ativação.
Treinando
Vamos treinar nosso modelo em 120 epochs, valor que pode ser alterado de acordo considerando capacidade de processamento da sua máquina, sua pressa e o desempenho desejado para a sua rede neural. Usaremos o algoritmo RMSprop para otimização.
Por fim, salvamos nosso modelo e o histórico de treinamento, e plotamos o histórico para ver a evolução da acurácia obitida pelo modelo.
Testando
Só lembrando: o nosso modelo deve prever a próxima palavra considerando as 3 anteriores, ou as SEQUENCE_LENGH anteriores. Por isso, precisamos de um texto prévio para a predição. Esse texto é preparado pela seguinte função:
Usamos a seguinte função para escolher as n palavras com maior probabilidade, conforme predição do modelo:
E fazemos a previsão assim:
Geração de linguagem natural
Nós ainda podemos usar o nosso modelo para fazer geração de texto automático. Tomando como entrada 3 palavras e gerando uma frase como n palavras, semelhante ao que fizemos com as Cadeias de Markov.
Conclusões
Nesse exemplo usamos como vocabulário apenas as palavras presentes no corpus de treinamento, que não é um número muito grande. Assim, se você quiser um modelo mais abrangente, precisa usar um vocabulário maior, como o do Freeling, por exemplo, ou de algum dicionário do português.
Pode ser que os resultados obtidos nos testes a partir da execução do nosso modelo, não sejam muito bons. Para melhorá-los, você pode tentar aumentar o tamanho do corpus de treinamento, a quantidade de épocas, ou utilizar Word Embeddings para a extração de features (Cenas dos próximos capítulos).
O código usado neste tutorial está disponível no GitHub.